Documentation
What Pipes is
Pipes is a spiritual successor to Yahoo! Pipes, but if you did not know that site, you can think of Pipes as a visual programing editor specialized on feeds, or a visual shell, or simply as a glorified feed configurator.
Pipes gives you blocks that can fetch and create feeds, and manipulate them in various ways. Think filtering, extracting, merging and sorting. All you need to do is to connect those blocks with each other. Data just flows through such a pipe, it flows from block to block. At the end Pipes gives you a new feed, which you can give to other programs that support open web standards - such a program could be your feed reader.
As input formats Pipes supports RSS, Atom and JSON feeds, it can scrape HTML documents, and it can work with regular text files.
How to use Pipes
At the left side of the editor is your list of blocks. You can drag and drop those into the canvas to your right, and the regular block with its inputs and outputs will appear. That block can again be dragged around, but more importantly, if you have multiple blocks you can connect their inputs and outputs. Those are the circles at the side of a block - left the inputs, right the outputs. To connect them, click first on the output of one block, and then on the input of another block. Or drag the input onto the output. You should also fill the user inputs, the form elements in the center of some blocks that control their behaviour. Don't forget to connect your last block to the pipe output, the red circle at the far right.
See the video above for a short demonstration of how simple it can be to filter an RSS feed.
Feeds vs Structured Data
There are two kinds of blocks: The feed type blocks assume that they work on RSS, Atom or even JSON feeds, which Pipes will normalize internally. Data blocks instead work on structured data represented by XML or JSON, they do not need a specific feed structure. Their usage is because of that quite different: Feed blocks will often limit the fields they can work on and just assume the typical fields (like the item title, or content mixed with description) are available. Data blocks can make no such assumption. They instead automatically analyse the structure of the input data and present field options via autocomplete in a slightly simplified JSONpath format.
As data blocks can work on all XML data, they can also work on the output of feed data (since RSS is a subcase of XML). But the other way around will not work in most cases. To limit issues with that, outputs of data blocks can not connect to inputs of feed type blocks - but the other way is possible, outputs of all feed type blocks can connect to input of data blocks.
Feed type blocks are the original way Pipes worked until early 2026. Data blocks were added then.
Pipe Output
For pipes using only feed type blocks, the default output format of a pipe is RSS. RSS is an open format which can be used in a lot of other programs, like feed readers. Each pipe has a pipe output url like https://pipes.digital/feed/pipeid which is shown in the editor of a saved pipe, or in the list of private pipes under My Pipes. If you want to get only the feed items' content you can open https://pipes.digital/feed/pipeid.txt, which will strip all xml feed elements. This is especially useful when your starting point was a text document that got transformed into a feed to work with its data in Pipes.
Pipes using data blocks default to XML as output format. It can be switched to JSON by adding json to the feed url, like this: https://pipes.digital/feed/pipeid.json, regardless of the original format of the data.
Support
Report bugs and feature requests via the Github issue tracker, or send an email to support@pipes.digital.
License and selfhosting
Pipes started as a non-free project. Now there is Pipes CE, a FOSS version of Pipes under AGPL, that you can run locally. Its home is the same Github Repository used as issue tracker for this site. You could think of this as an open core model.
Blocks
Feed
Download a RSS, Atom or JSON feed. If not pointed directly to the url of such a feed, it will try to find a <link rel="alternate"> element in the head of the linked page, and then download that feed. The feed block is usually the starting point of a pipe. Note that Pipes caches all downloads for a few minutes.
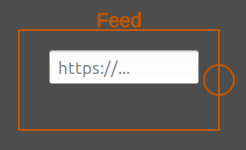
It has no block input, but it takes as user input the url to download.
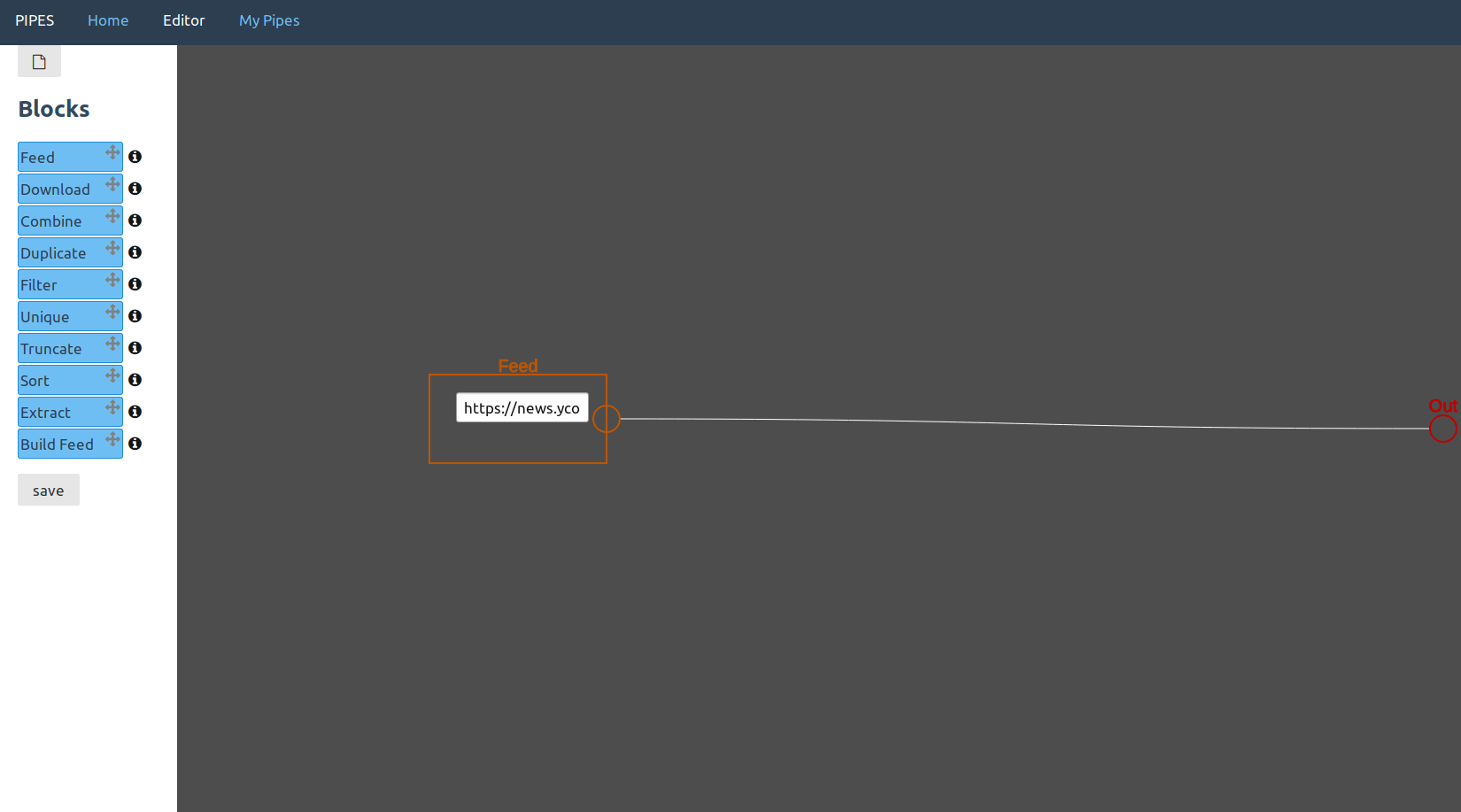
In this example usage, the pipe consists of only one single feed block. That's not very useful yet. But note that the feed block input points to a normal HTML page, not an RSS feed. Because Hacker News specifies its RSS feed as a rel="alternate", this pipe will output that feed instead.
Filter
Filter the input feed for a keyword, and either show only items that contain it or filter them all out. It searches for the word in the items title, description (if existing) and content. The search is case sensitive. If given a regular expression, it will interpret that regular expression instead, enabling more powerful filtering. Write that expression as /expression/, but regular keywords without the outer slashes.
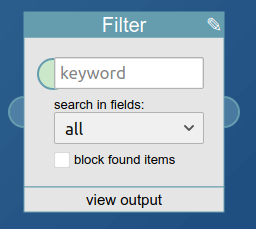
It takes the feed it searches through as block input, and the keyword to search for as user input. The second input, the checkbox, toggles whether found items are to be included or to be blocked.
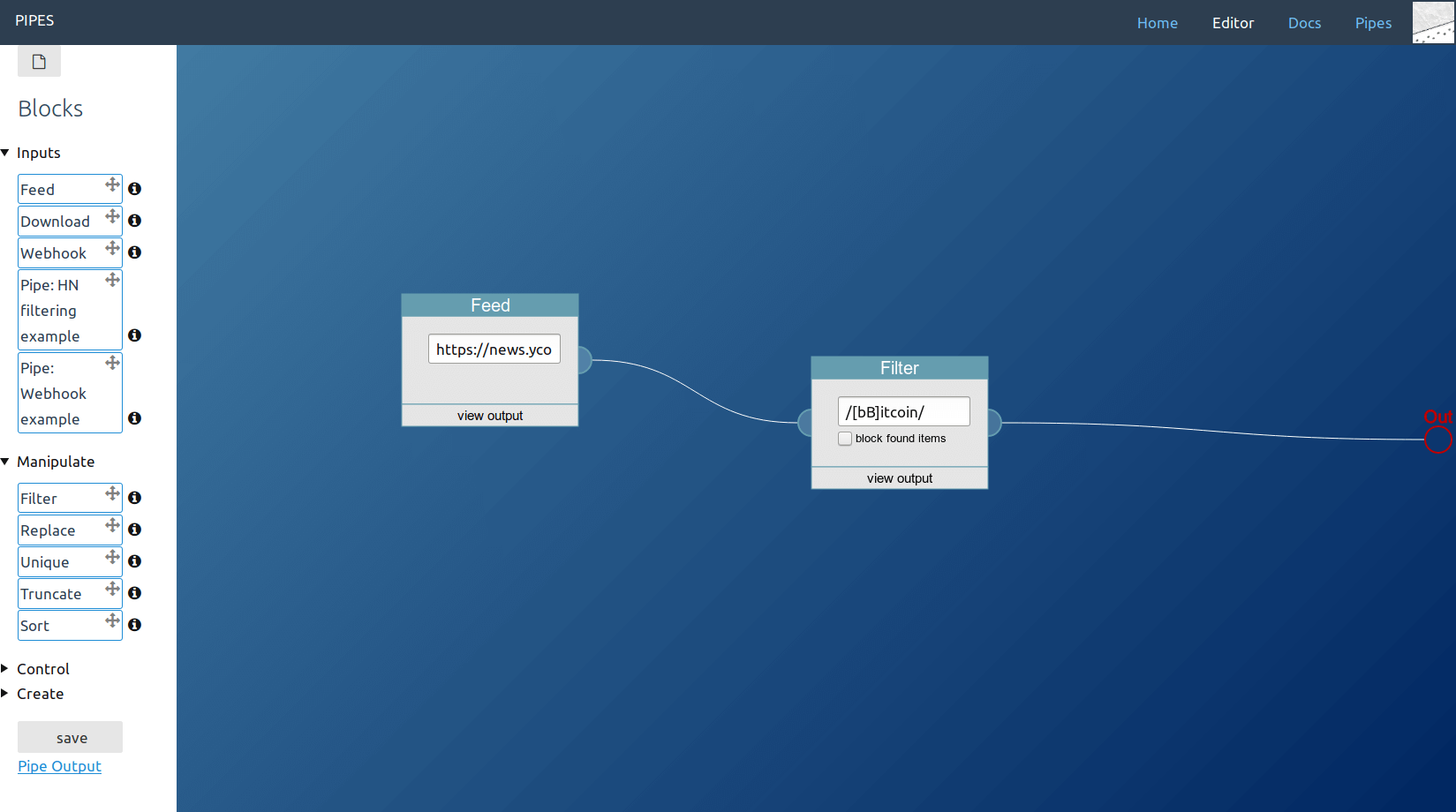
In this example usage, the filter block will filter the downloaded feed for all items that contain the keywords "Bitcoin" or "bitcoin".
Filter (structured)
Remove fields from the input data. You can base the decision either on the value of a specific field or on the value of a child of the field. Either remove only items that contain a keyword (case sensitive), or remove all items of the same path that do not contain the value, or use a regular expression. You select the fields this works on with a JSONpath. The search is case sensitive. In regular expression mode, write that expression as /expression/.

It takes the data it searches through as block input. The first user input is to specify the fields to filter via a JSONpath. The second input, the first on the second line, can optionally be used to specify the child field on which the filter decision should be based. The third input, the second on the second line, contains the keyword or regular expression used for the filtering.
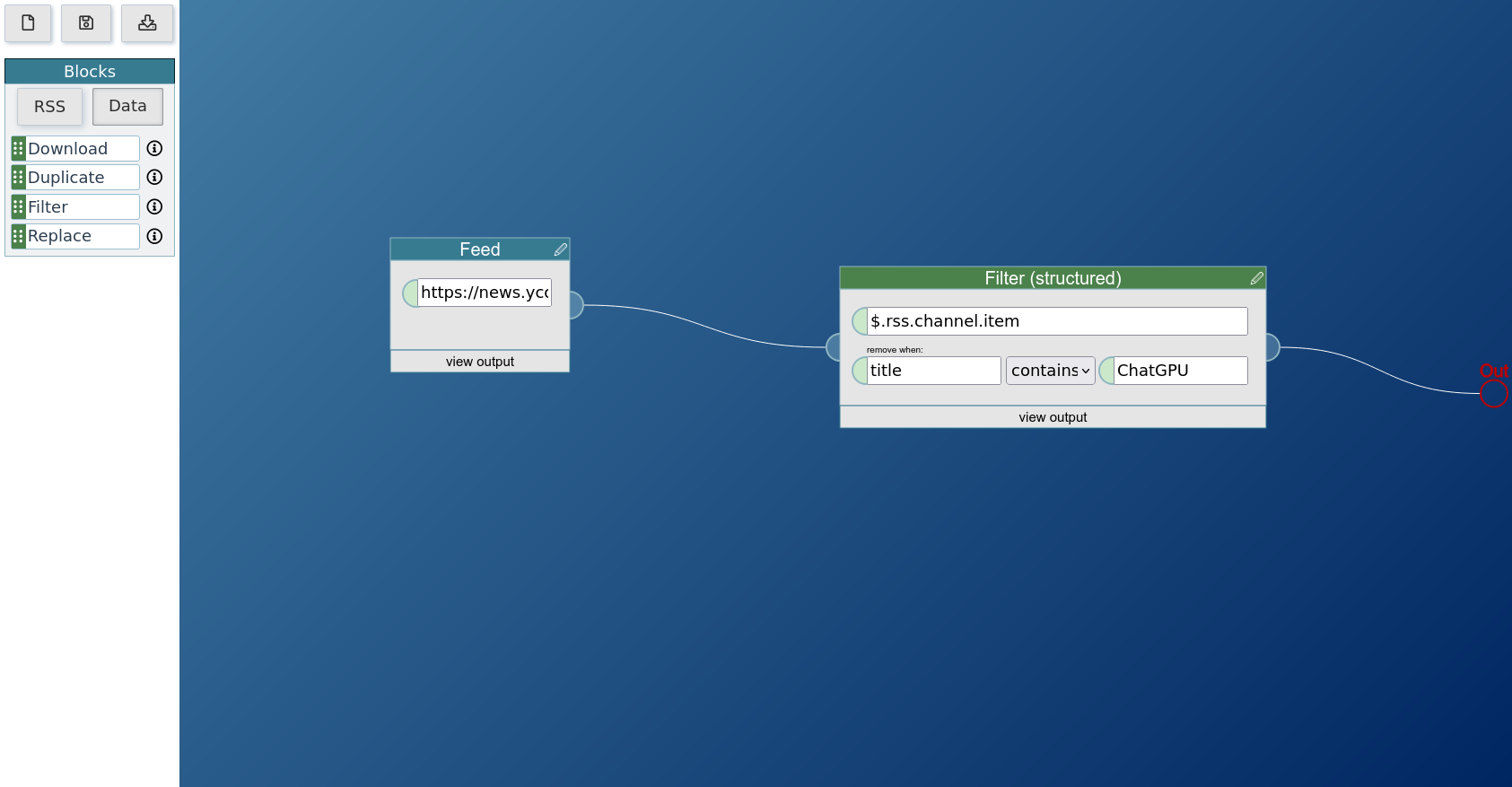
In this example usage, the filter block will remove all items from rss.channel if the items have a title field that contains the word ChatGPT.
Filter Language
This block checks all feed items for their language they are written in. The default logic is to keep only the items in the selected language. It checks multiple fields of an item for that, but you can limit the check to some specific fields, like only the title or only the description. And with the last checkbox you can turn the logic around and remove all items that are in the selected language.
Use this block if you have a multi-language feed and you want to only keep items in your target language, or remove items in the one language that does not work for you. Be aware that the used n-gram detection will not be 100% accurate, and it even will be very inaccurate for very short texts (less than 10 words is bad, 5 should be the absolute minimum).
Replace
While the filter block is like the search tool grep, the replace block is like sed or the replace function of your texteditor. The first input is the search pattern, the second is its replacement. If given a regular expression, it will interpret that regular expression instead, enabling more powerful filtering. Write that expression as /[aA]bc/, as a regualr expression with surrounding slashes. The replacement pattern supports backreferences (\1).
It takes the feed it searches through as block input, and the regex-enabled keyword to search for as first user input. The second input is its replacement pattern.
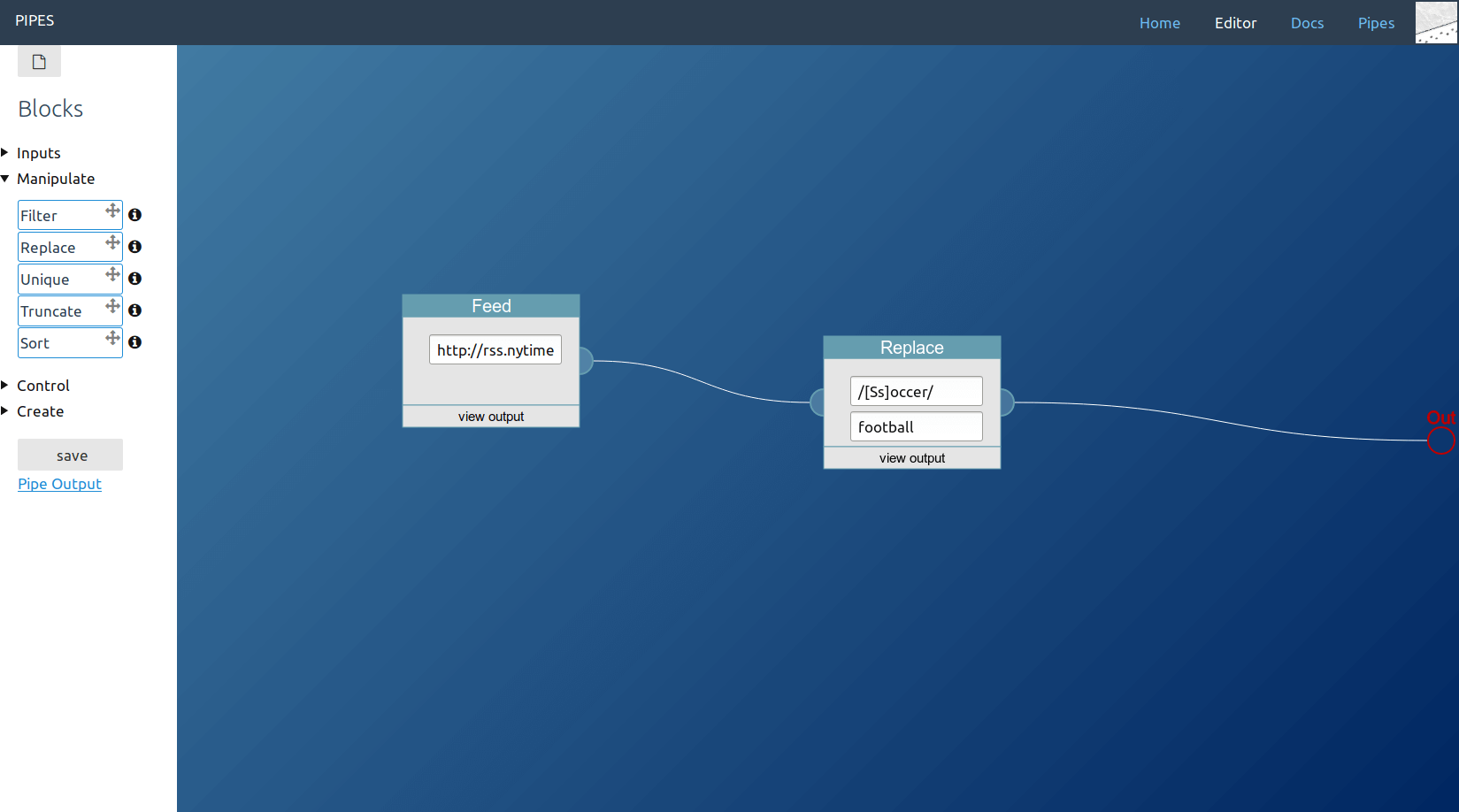
In this example usage, the replace block will search the downloaded feed for all items that contain the pattern "soccer" or "Soccer" and replace those occurences with "football".
Replace (structured)
This works very similar to the replace block for feed data, but operates more freely on structured data given as XML or JSON. The first input is the search pattern, the second is its replacement. If given a regular expression, it will interpret that regular expression instead, enabling more powerful filtering. Write that expression as /[aA]bc/, as a regualr expression with surrounding slashes. The replacement pattern supports backreferences (\1).

It takes the data it searches through as block input, and the regex-enabled keyword to search for as first user input. The second input is its replacement pattern. The third field specifies in which field values should be replaced, given as an autocompletable JSONpath.
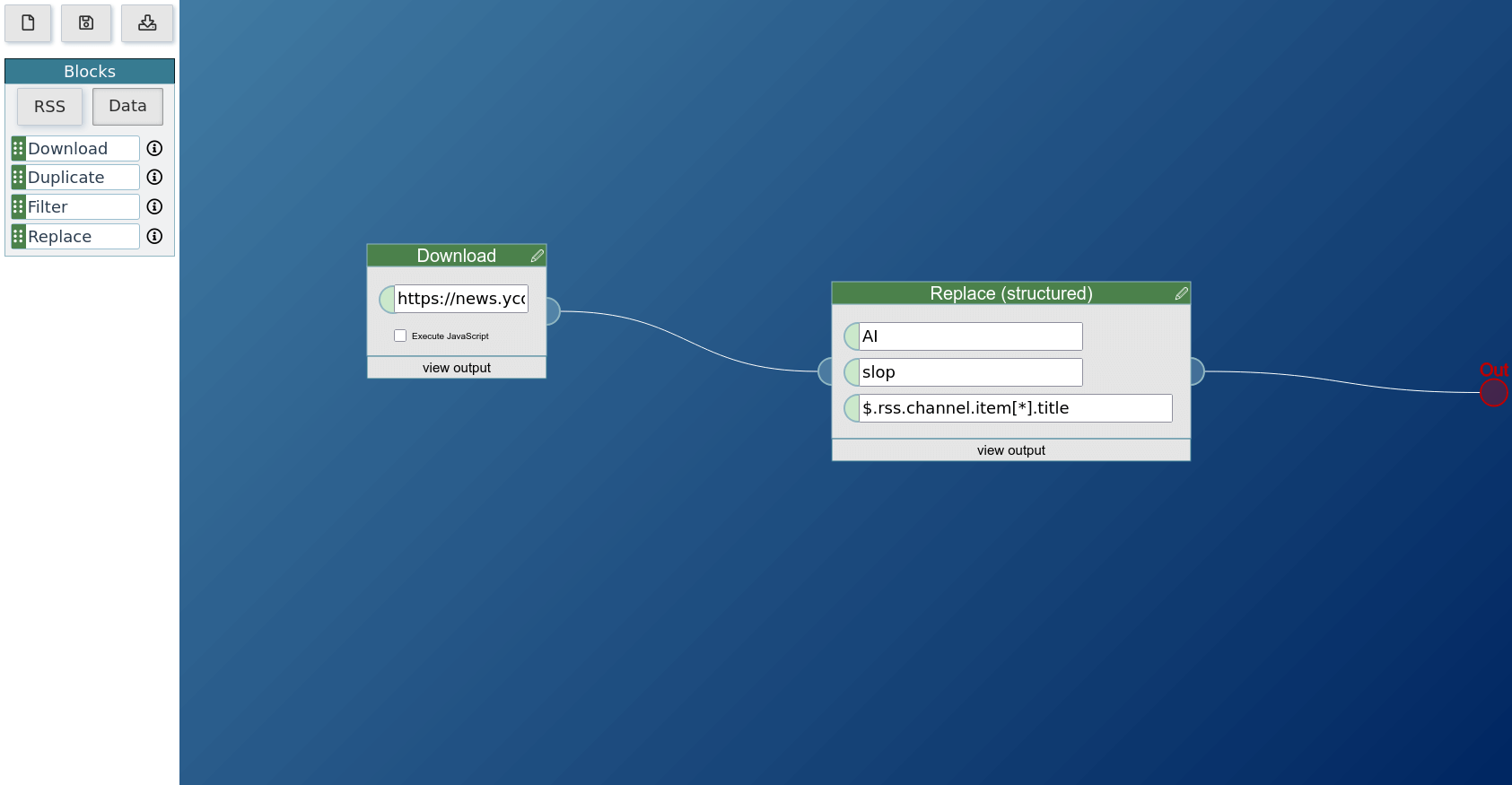
In this example usage, a feed is downloaded as structured data and the replace block transforms "KI" to "slop" if it occurs in the selected title field of a channel item.
Combine
Combine two or more input feeds into one single feed. Combining those feeds will merge their items lists, and will also append their feed title and descriptions. The sort order follows the input order: The output feed has first all items from the first input feed, then all items from the second input feed, and so on.
It takes the feeds to merge as block inputs, and has no user input.
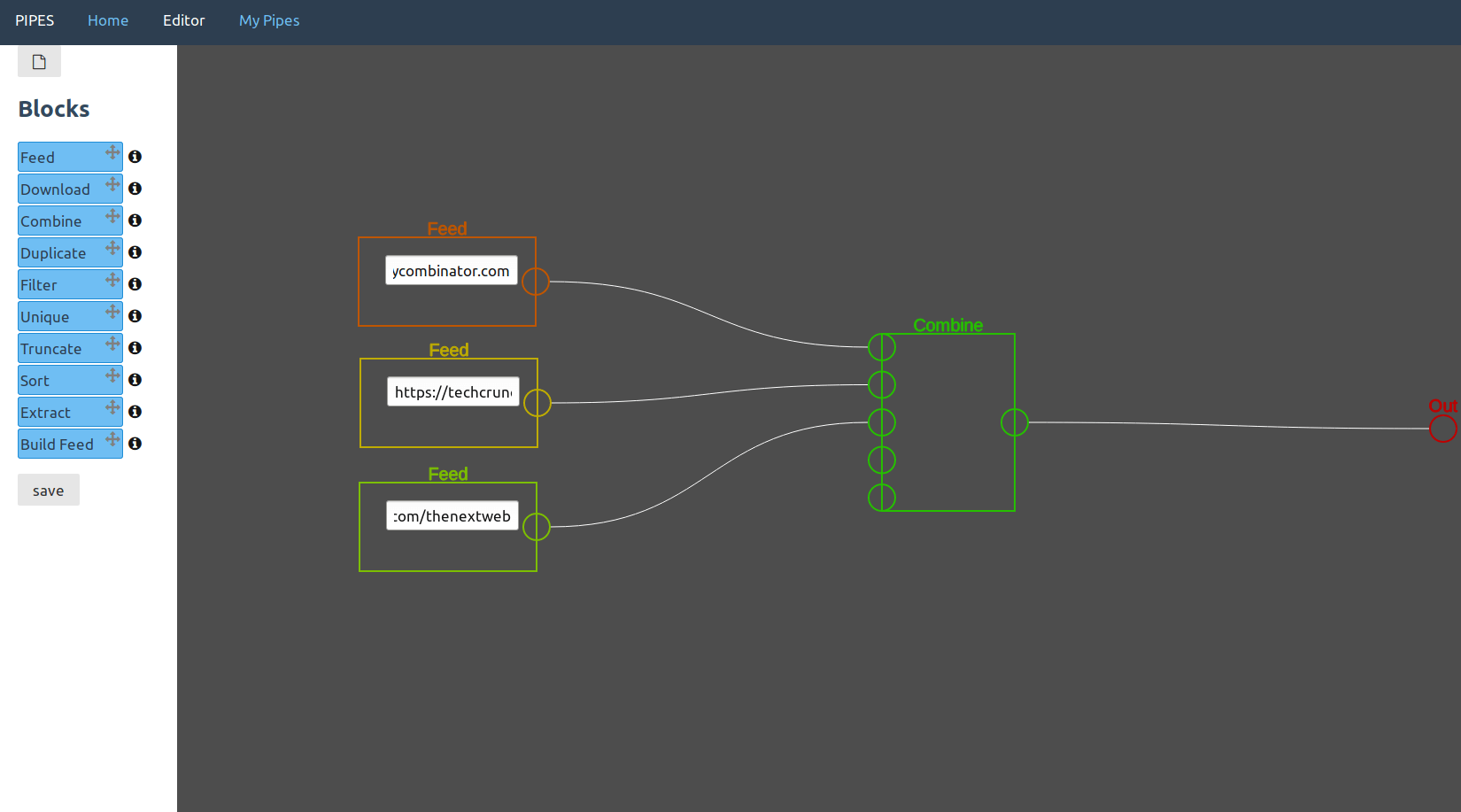
In this example usage, the pipe downloads multiple feeds and then combines them together.
Duplicate
Duplicate the input feed into multiple output feeds. You can also think of this as a splitter. This block does not manipulate the input feed in any way.
It takes one feed as input, and has no user input. This is the one block that has multiple outputs.
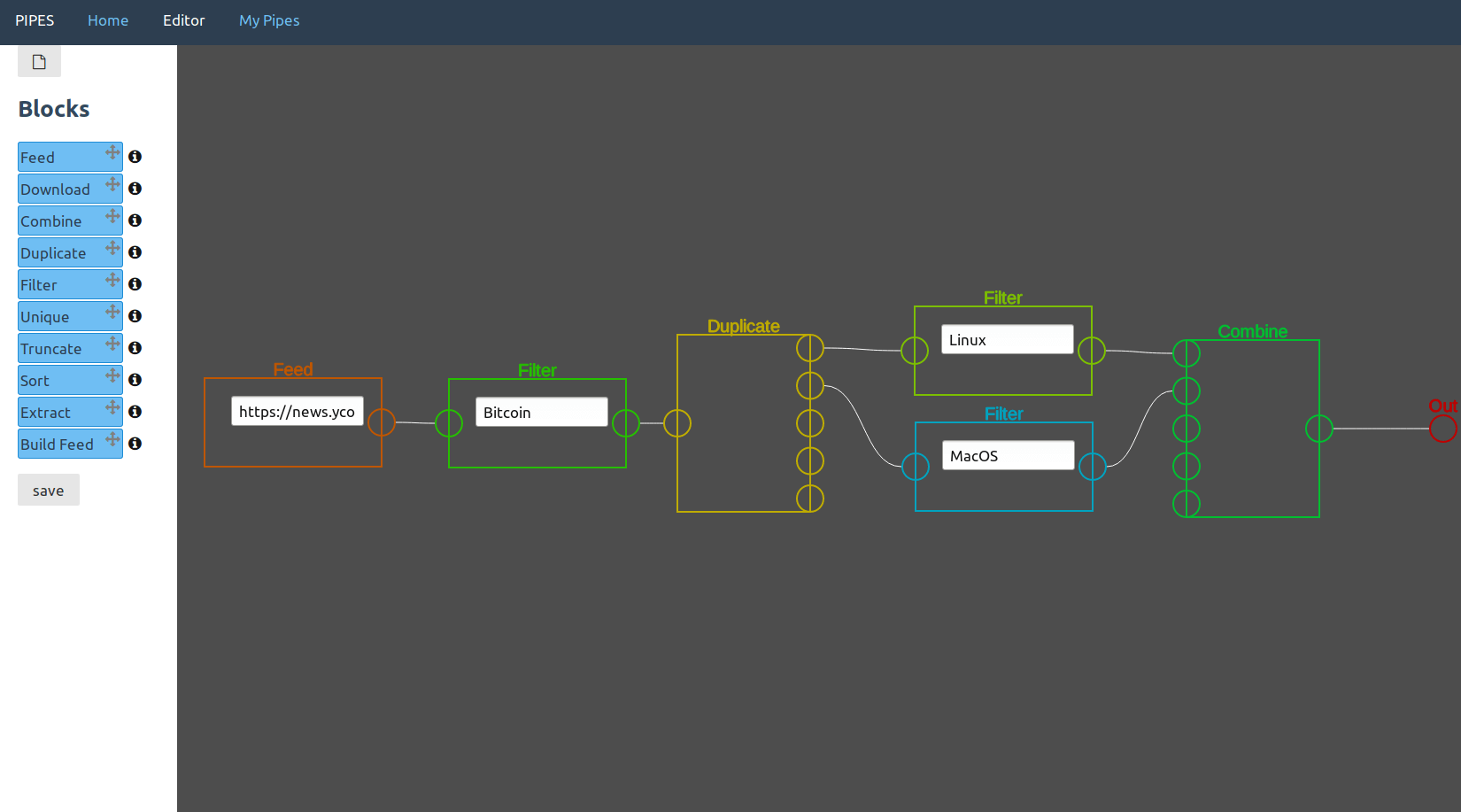
In this example usage, the duplicate block duplicates a feed that was already filtered for "Bitcoin", to filter it as well for "Linux" and "MacOS". Those two feeds then are combined together.
Merge Items
Use this block to merge items together. It will take step by step one item from each input feed and merge them together into one single item. You can optionally specify a replacement format. If it contains \1 and \2 it will replace those with the content of the two items. If it is just a regular string, then that string will be between the two item contents. If it is empty they will just be concatenated.

The block takes two feeds as input. The user input serves as format, as replacement pattern, but is optional.
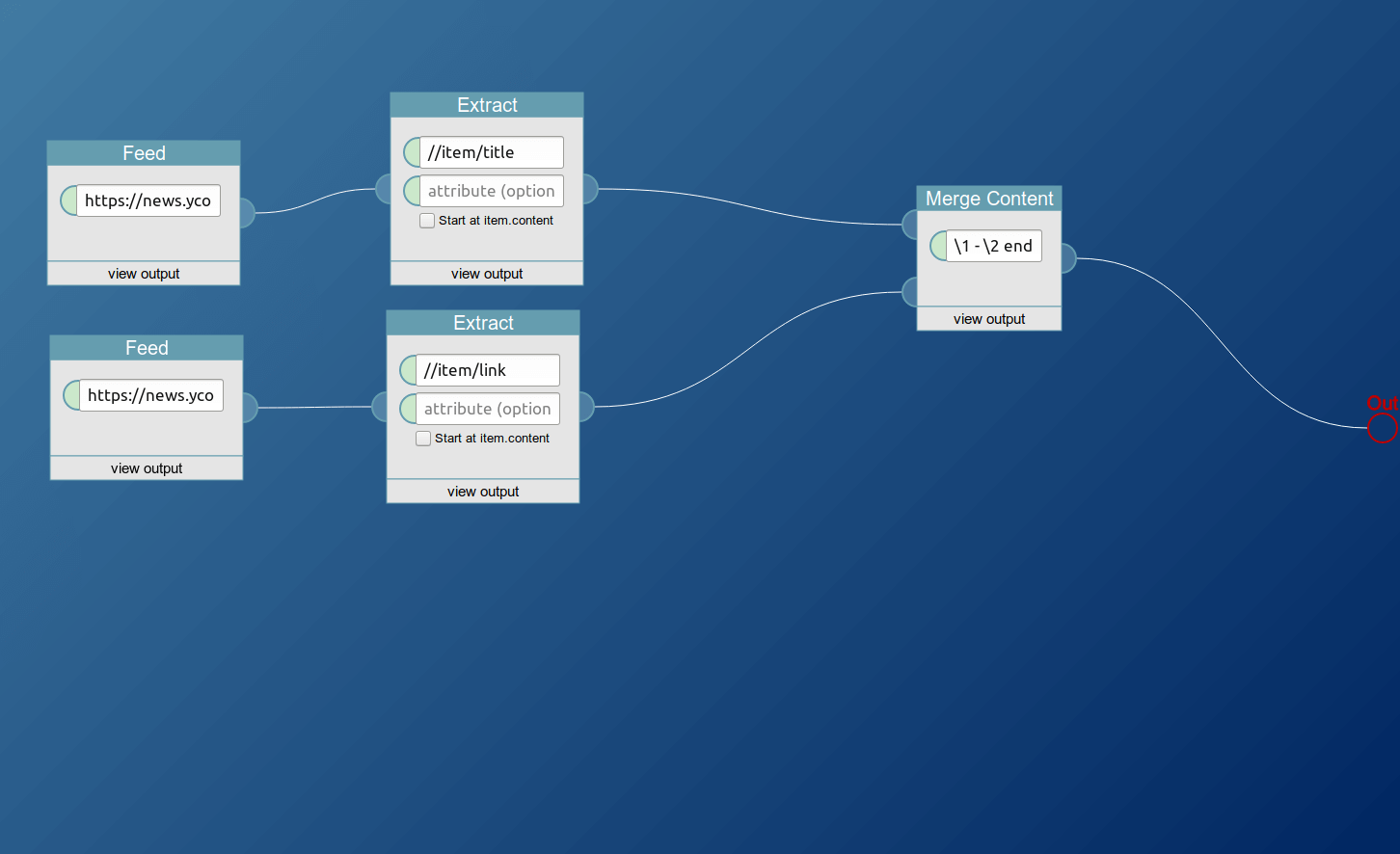
In this example usage the title and the link of the hacker news feed are placed after one another, a dash is between them and an end added.
Unique
Remove duplicate items from a feed. Duplicate items could be an accident in the original feed, but more likely is that they occur after merging filtered feeds with items that containing multiple search words. This block uses the items guid to determine that two items are equal.
It takes one feed as input, and has no user input.
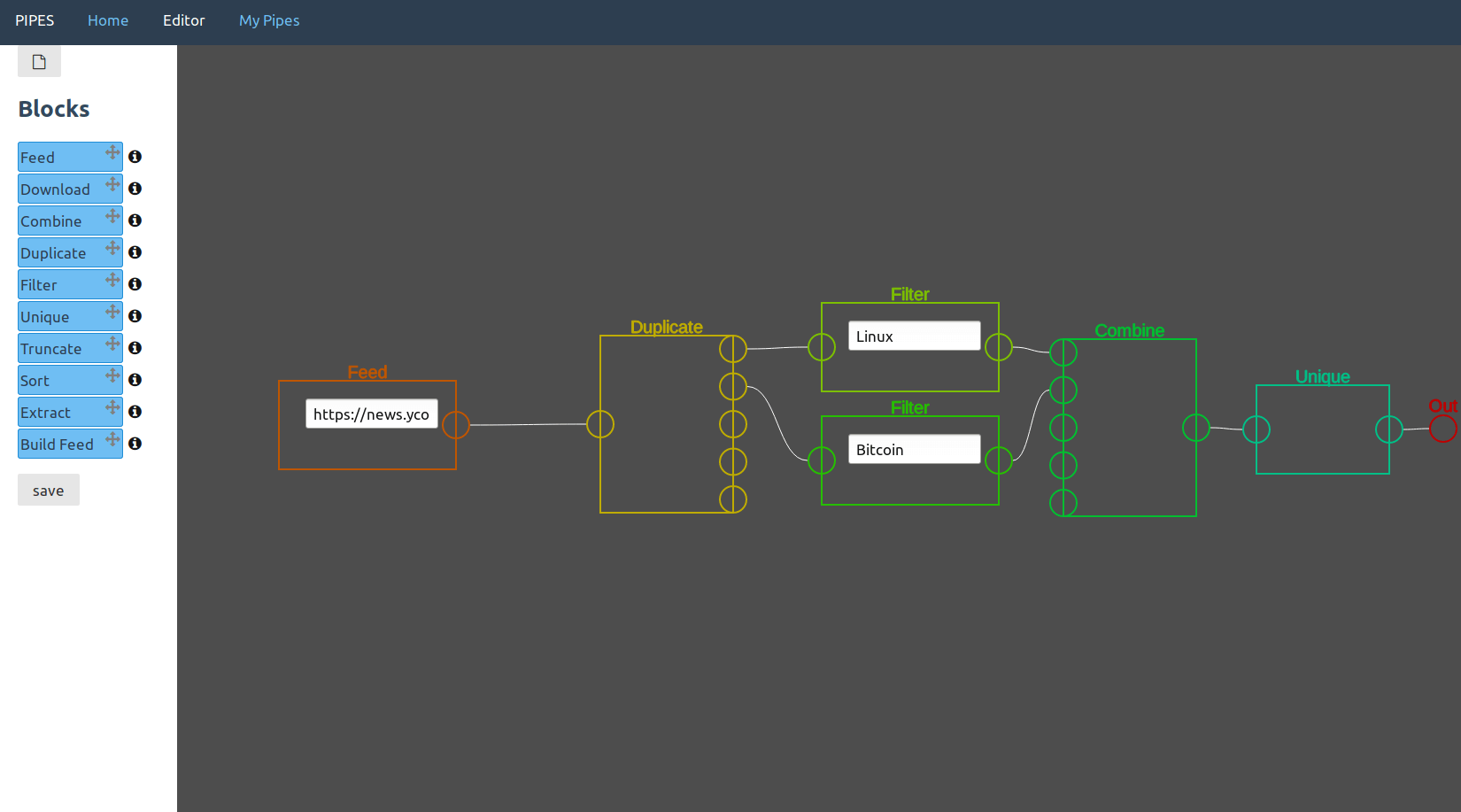
In this example usage, the pipe downloads a feed, duplicates it, filters for "Bitcoin" and "Linux" and then merges the results. The unique block now makes sure that items that contain both "Bitcoin" and "Linux" occur only one time in the output feed.
Truncate
Truncate an input feed to a given length, with the first x items remaining. This is unlikely to be very helpful in a pipe, apart from when an input feed is really long and you want to improve performance. But imagine you have a website and want to show the last few items of a specific feed, then you could make that easier by producing a feed that has exactly as many entries you want to display.

It takes one feed as input, and the target amount of items as user input.
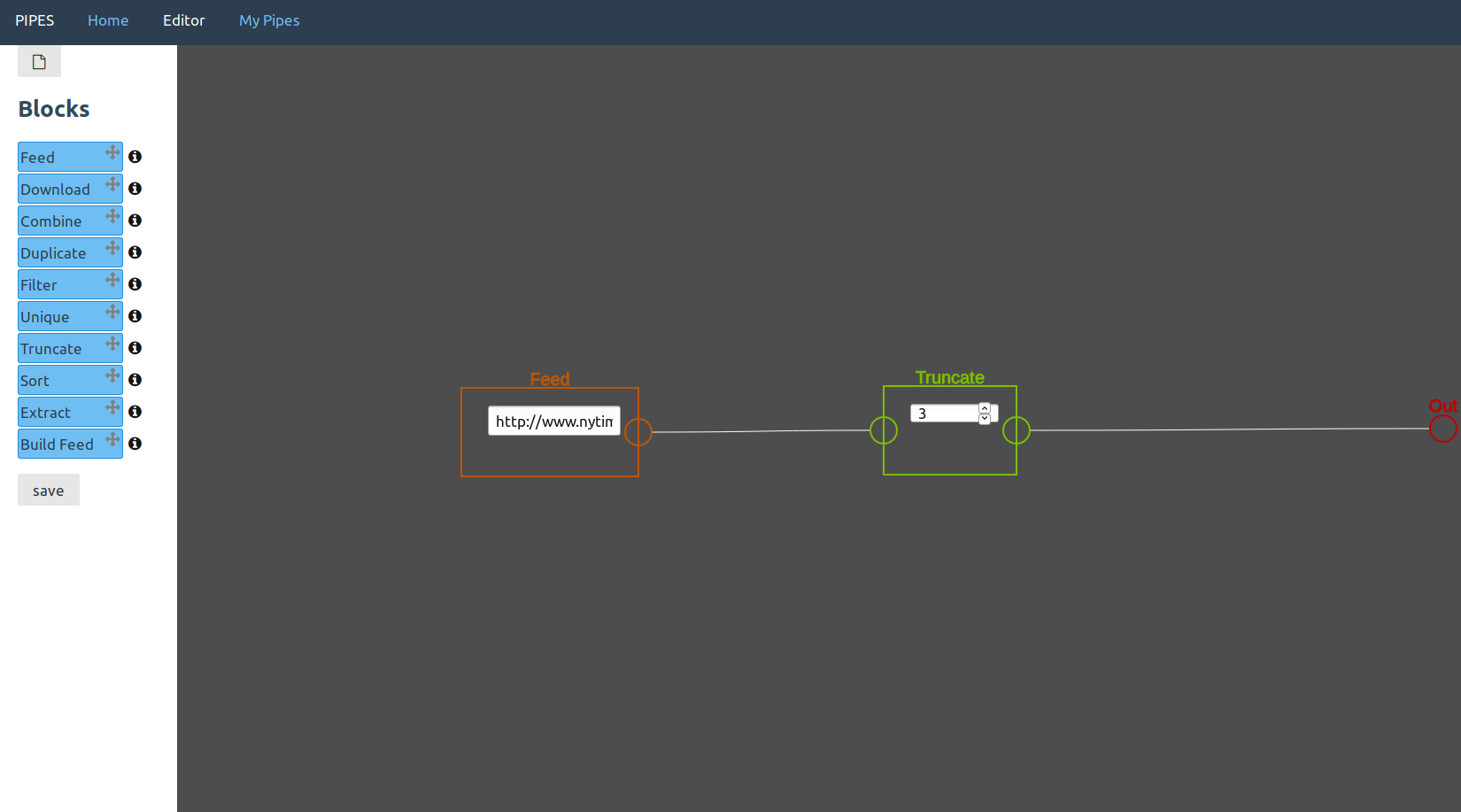
In this example usage, the feed of the New York Times homepage gets truncated to three items.
Shorten
Shorten the text inside the selected element. The number defines how many characters are the target text length.
Sort
Sort the items of an input feed. You can specify the sort order, and which item element to use for sorting. Default is to sort by the items date (its updated element).
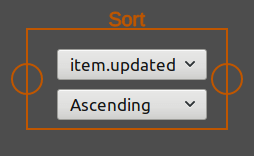
It takes one feed as input, and two user inputs to set the sort order and the sort item.
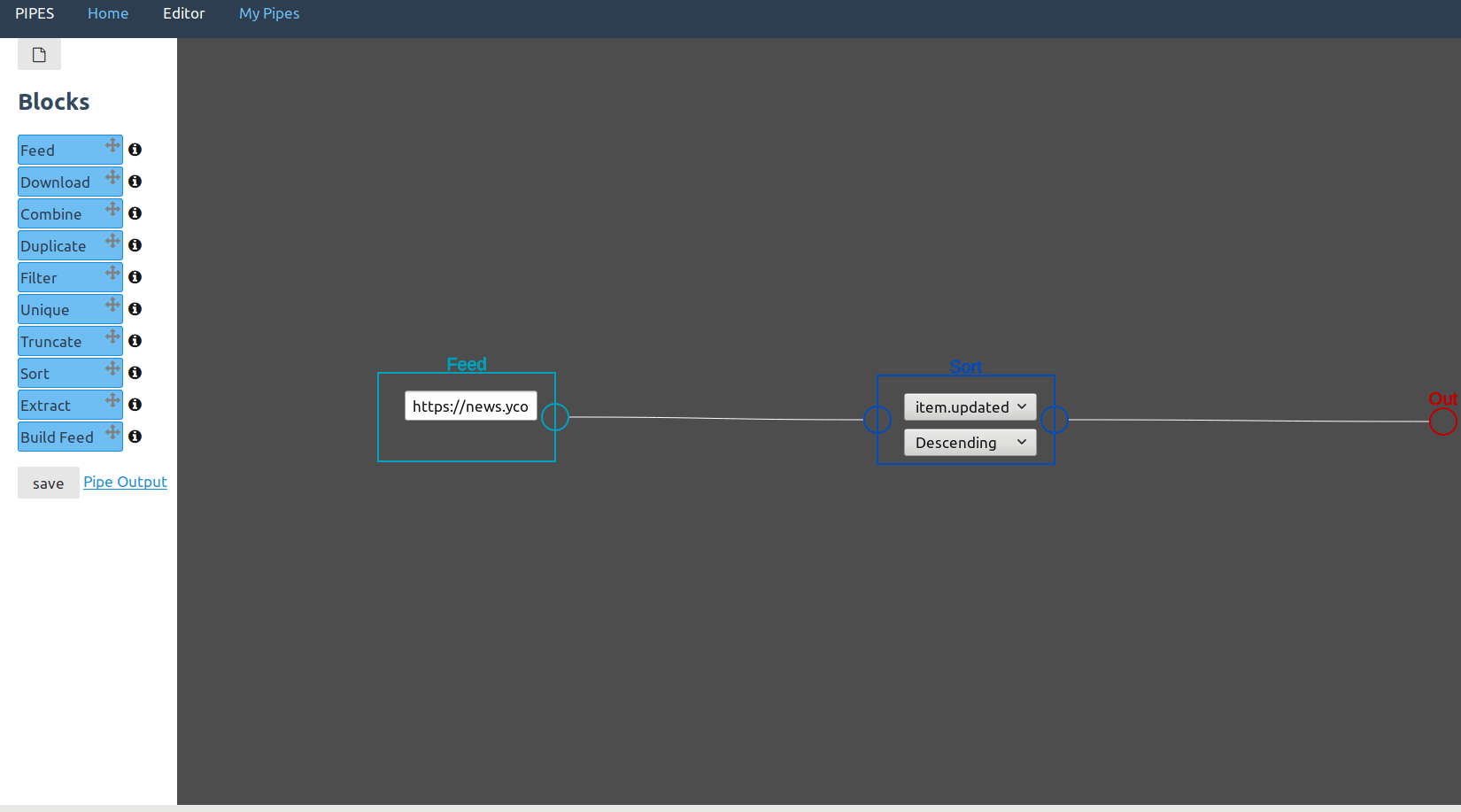
In this example usage, the Hacker News feed is re-sorted by date, to have the newest items at the top of the list.
Download
Download a page. This is different from the feed block as it will not try to find a feed. This block is really meant for downloading some data, like a html page, that is then transformed by other blocks to create a regular feed. As such the this block then needs to be connected to the extract block or the builder block, to create a regular feed. It is an alternative starting point for a pipe. Note that Pipes caches all downloads for a few minutes.
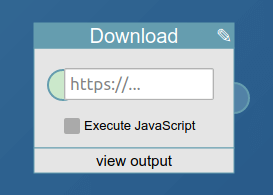
It has no block input, but it takes as user input the url to download. If on a paid plan, it also allows setting a checkbox to interpret javascript on the downloaded page.
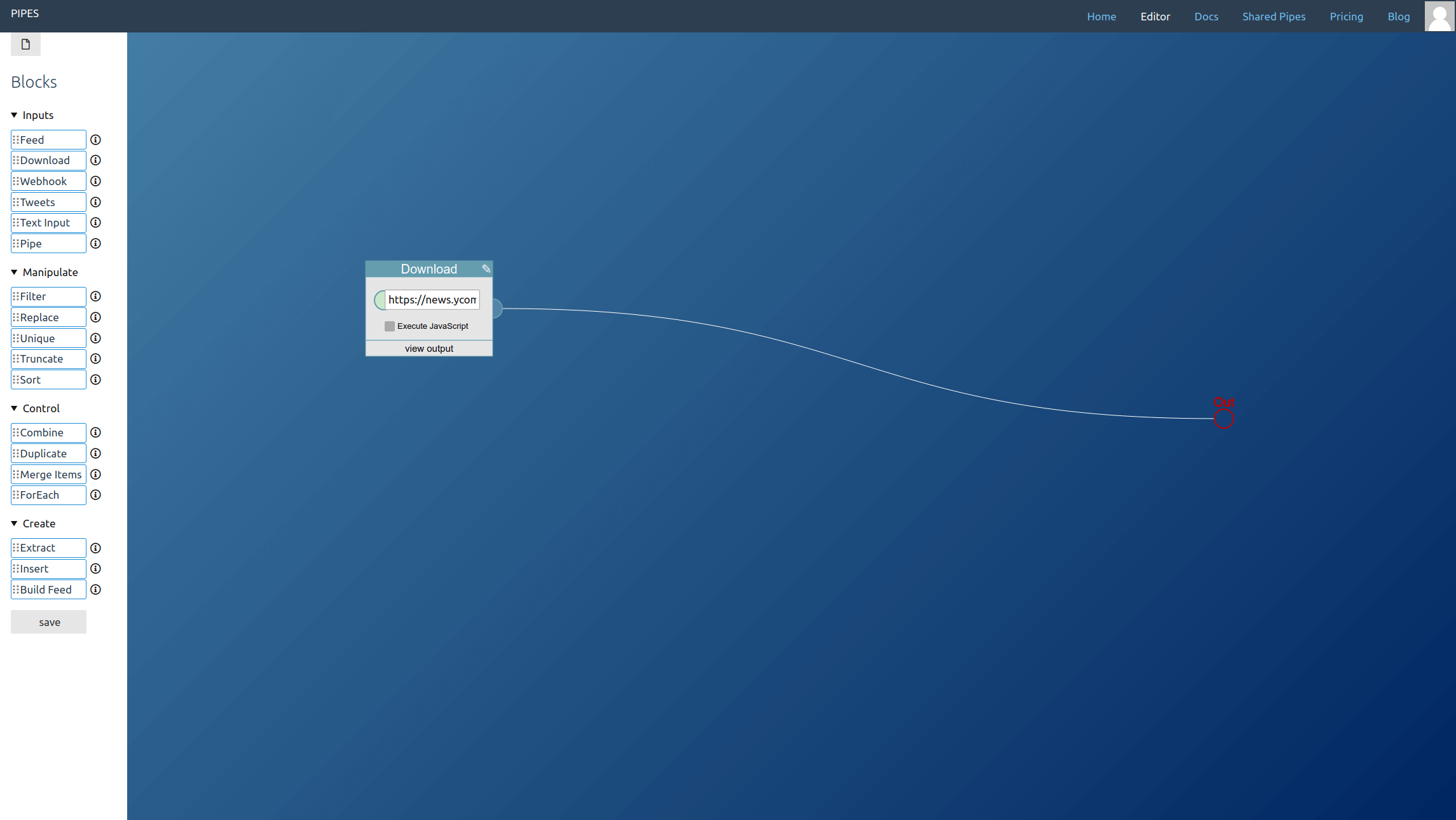
In this example usage, the Hacker News page is downloaded and set as feed output. That's not really useful yet. But note that it really is the Hacker News website that the pipe downloads, not its feed.
Extract
Extract content from a feed, downloaded HTML page or from downloaded JSON. You can use XPath for XML, css selectors for HTML and JSONPath for JSON to select items, and select whether to extract their content or an attribute (which has no effect with JSONPath). If you have a feed which contains data in its item.content - think JSON data in the RSS feed generated by the webhook block - then you can enable start at item.content to use i.e. a JSONPath to get your data out of the XML feed. All matched elements will be the content of the items of a newly created RSS feed, which becomes this blocks output.
It takes one feed, or preferably a downloaded HTML page, as input. The css selector or XPath expression is the first user input, the second is to select an attribute instead of the default element content. The checkbox at the bottom control whether the search expression is used for the whole input data, or only for the data in the input feeds item.content.
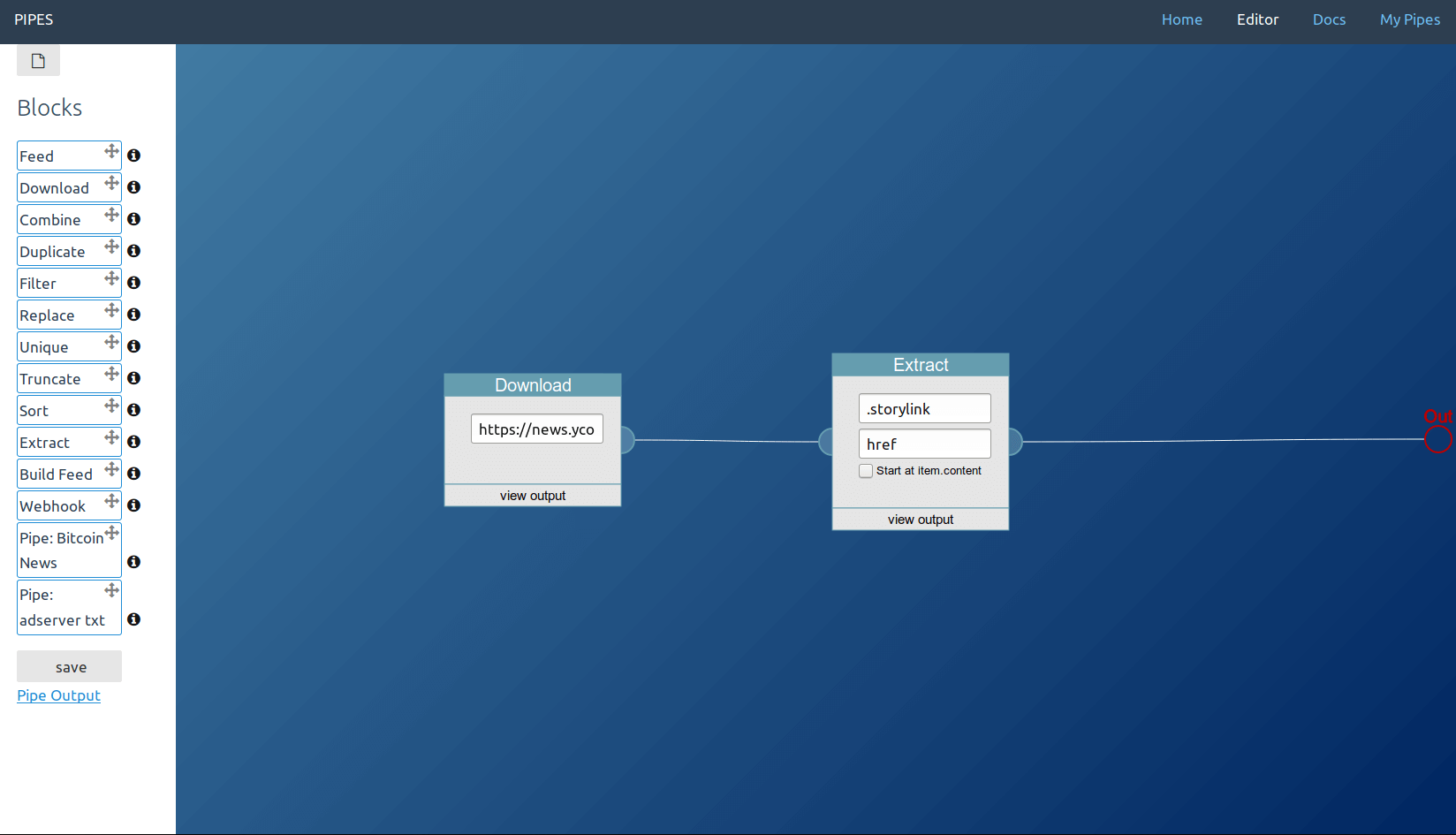
In this example usage, the link targets of the articles on the Hacker News homepage are extracted and set as feed output.
Images
Extract images from a feed or a downloaded HTML page. The block will select all images currently embeded into the page or feed items. It also gives access to a gallery that opens in an overlay and shows all the images selected. Just for displaying those images and not as block output, the gallery will try to create absolute urls for those images that on the source page were linked with relative urls.
It takes one feed or downloaded HTML page as input. The output is a feed with each item containing one image.
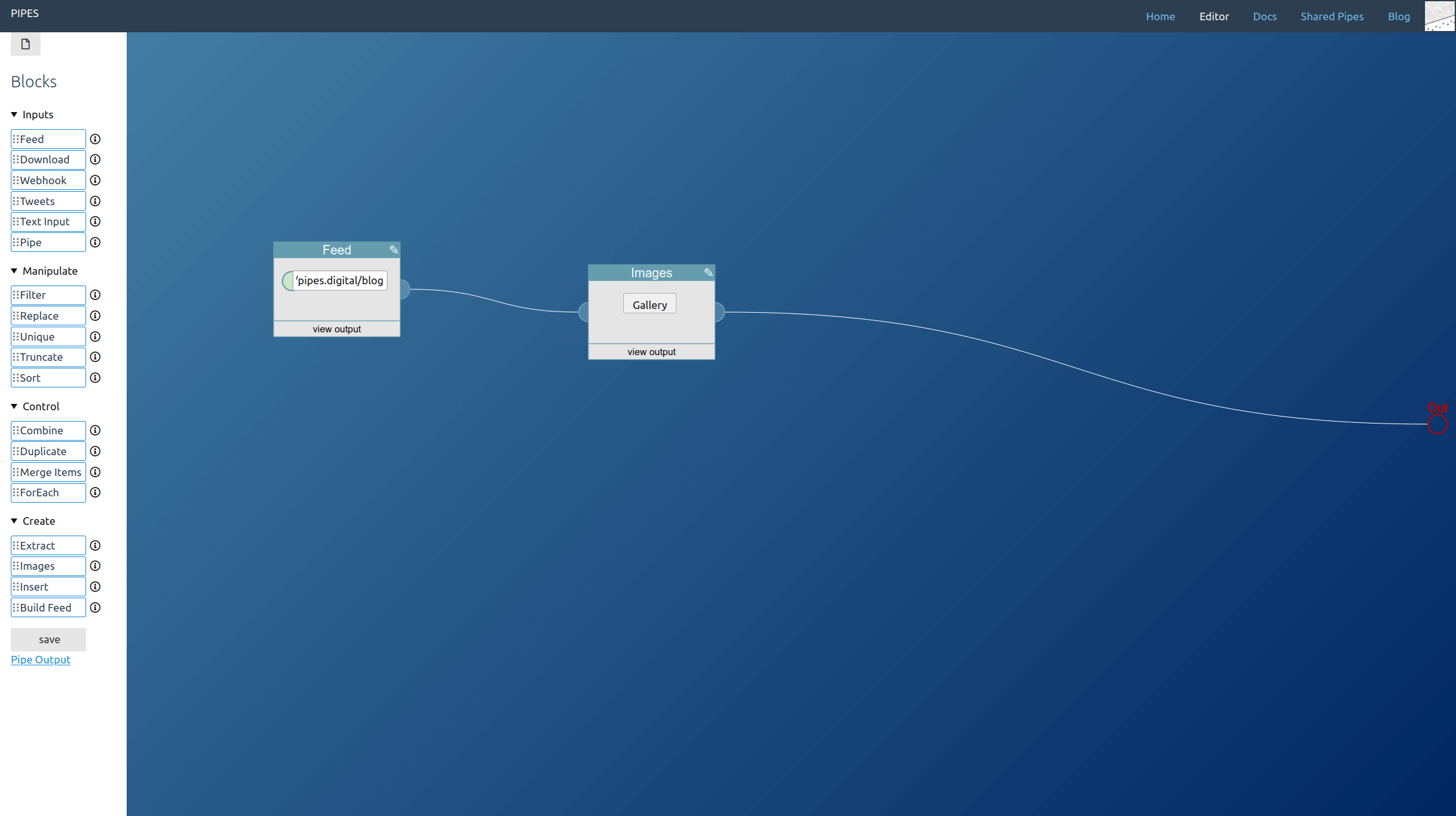
In this example usage, the images of the articles on the pipes blog are extracted and set as feed output.
Tables
Extract HTML tables from a feed or a downloaded HTML page. The block will select all HTML tables currently embeded into the page or feed items and convert them to JSON. It then outputs a feed with only the JSON tables as item content.
It takes one feed or downloaded HTML page as input. The output is a feed with each item containing a JSON object.
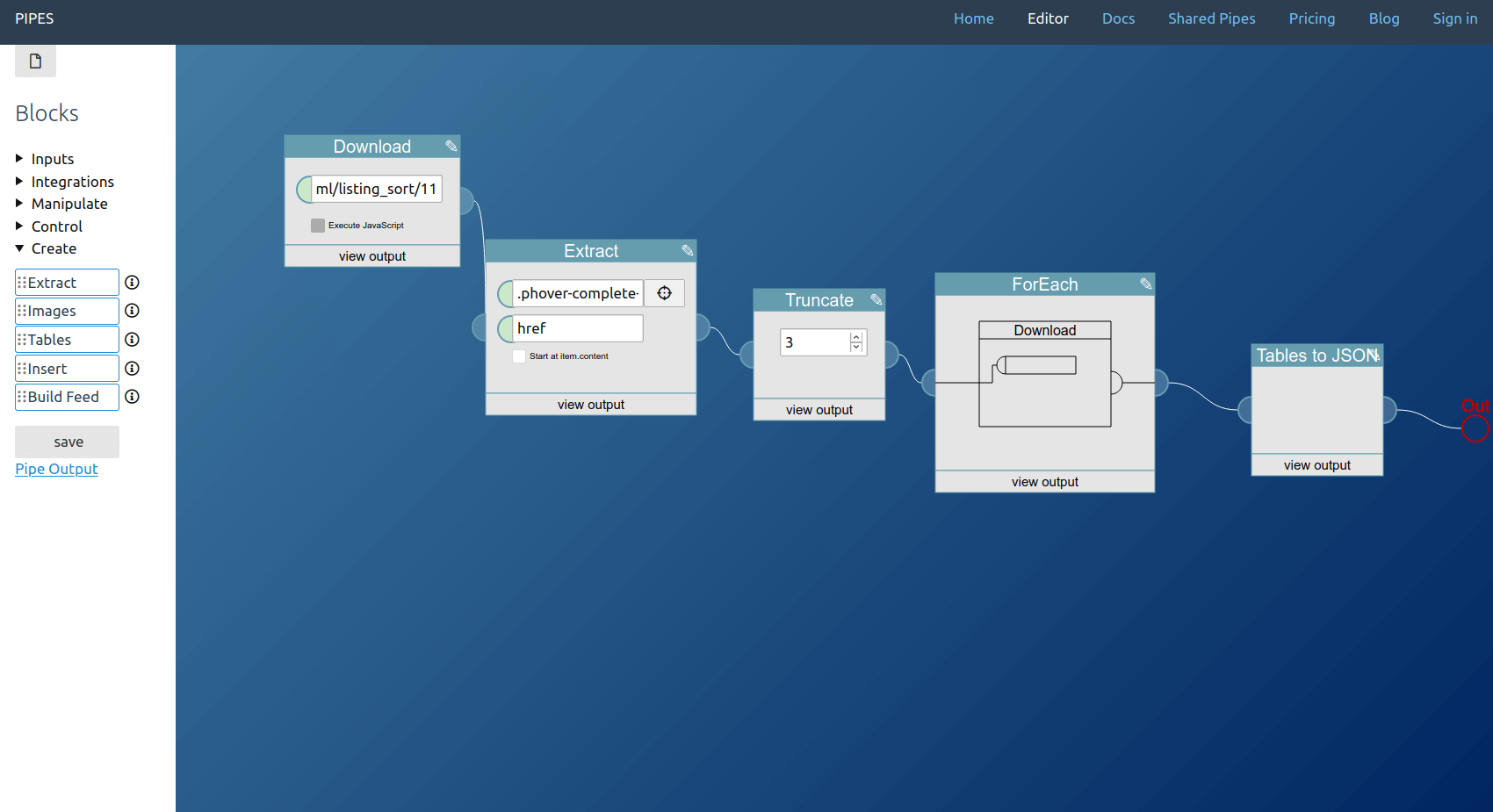
In this example usage, the tables of a crawled page are extracted and set as feed output.
Insert
Insert content taken from one feed and insert it at the specified position of a different feed. This is meant to be combined with the extract block. Take something from one feed with the extract block, connect it to this block, and then connect the feed where you want to add the extracted element.
It takes two feeds as inputs. From the first it will take the first item, the second input is the feed that will be modified. The XPath expression specifying where to insert the element is the user input. The third input, the checkbox, toggles whether the new content should be appended to the already existing content at the target item or whether to replace it.
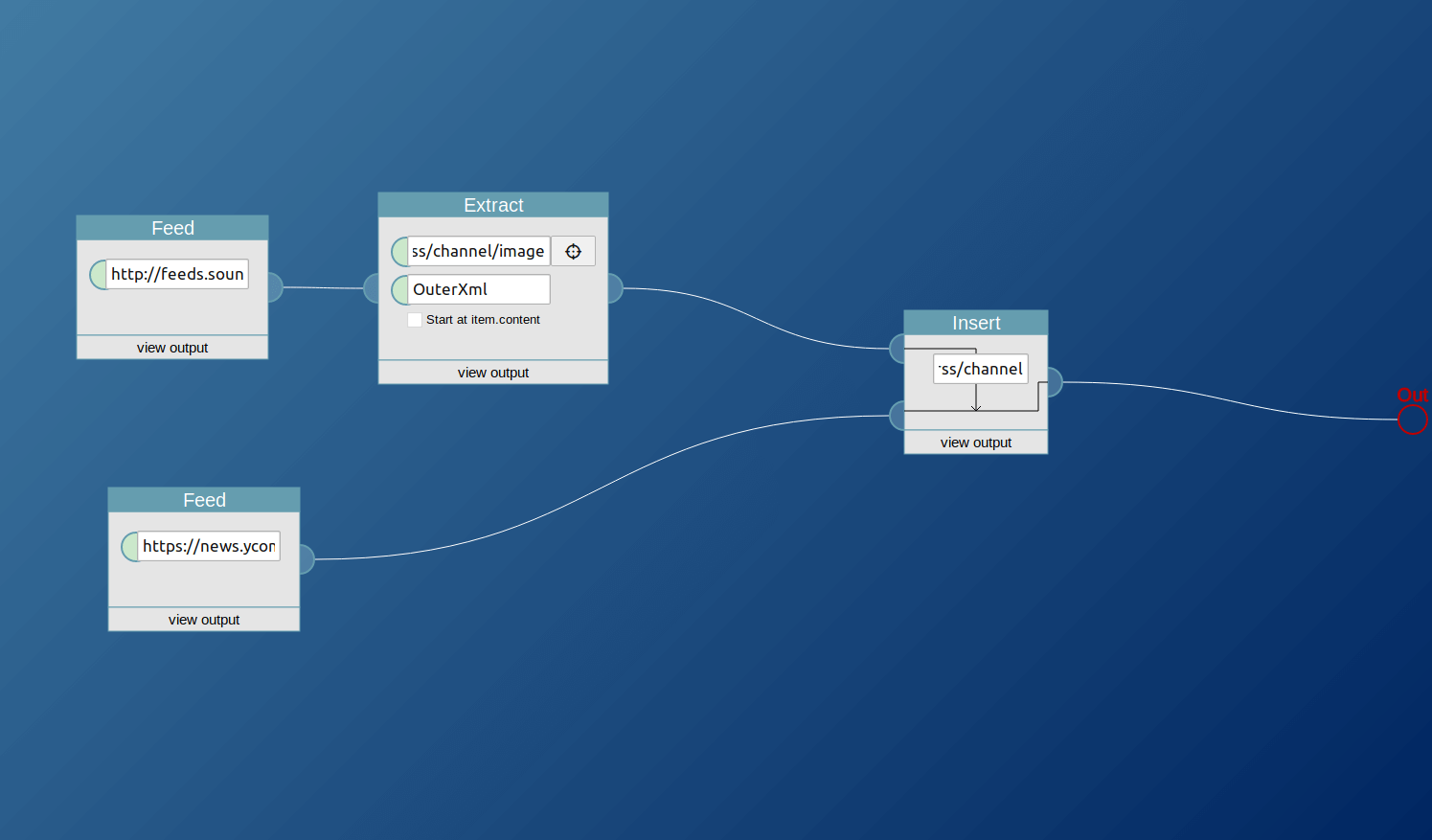
In this example usage, the /rss/channel/image node of a soundcloud feed is taken and inserted into the Hacker News feed.
Build Feed
Build a new feed. The various input feeds are set as its items attributes. That way one can use extracted elements to create a new regular feed, whose items have a proper title, content, date and link. You can also connect a downloaded text file to this, that will then get transformed line by line into feed items. The order is important here: this block will go through all its input feeds simultaneously, and at each step get the content of the current item of the content feed, as well as the content of the current item of each other connected feed, to create a complete feed item. This block can be used in various ways, but its most obvious usage is to create a feed for a website that has no feed of its own.
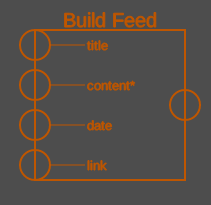
It takes four feeds as input, and the markings in the block show which attribute they will fill. The second input for example will become the new feeds content, and is the only required input.
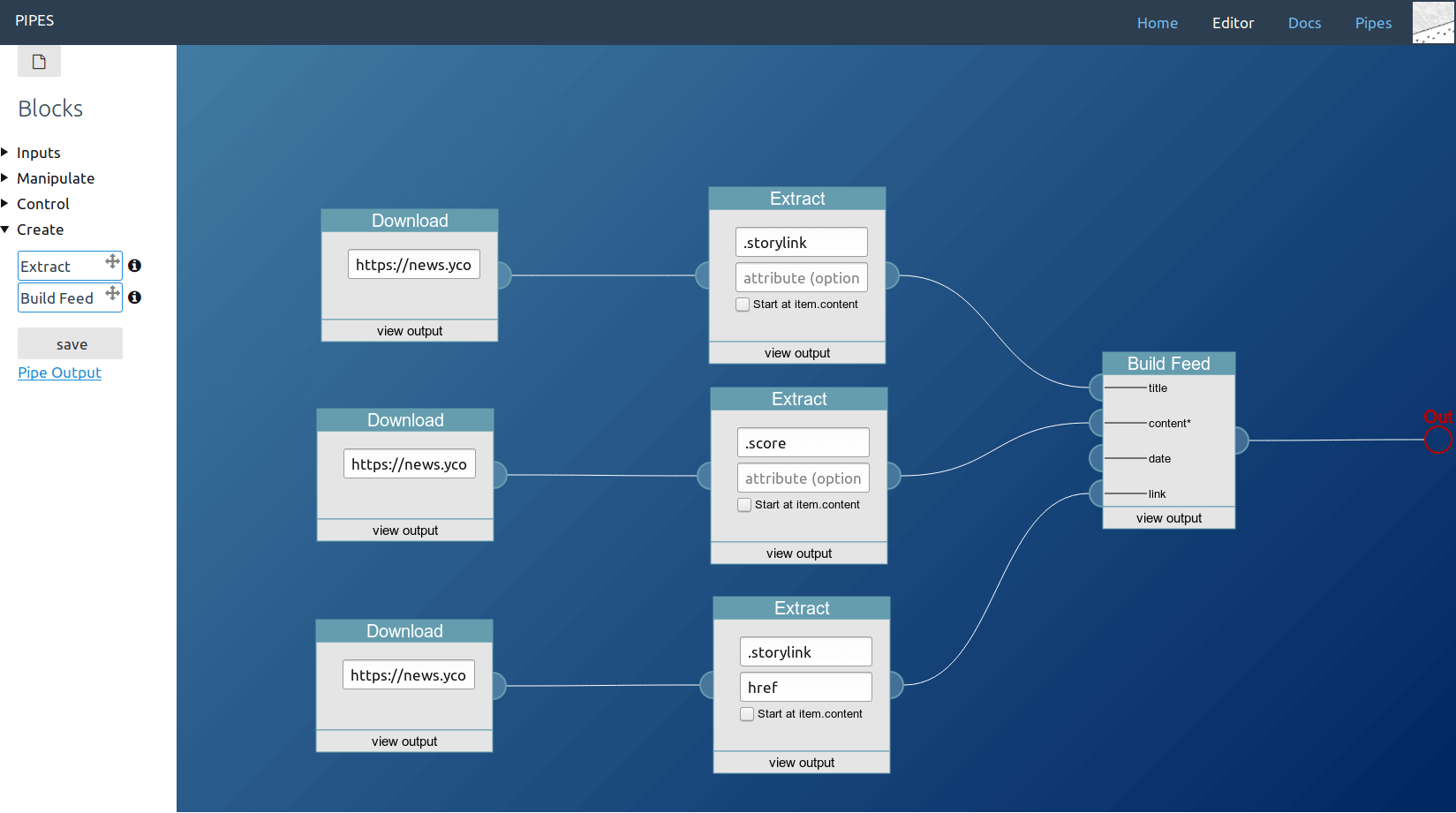
In this example usage, the pipe downloads the Hacker News homepage, duplicates it and extracts three elements: The title, the score and the link target. Those are then given to the feed builder to set the new items title, their content and their link target.
Pipes as Blocks
Use a pipe as input block. Since pipes output RSS, their feed can effortlessly be used in other Pipes. This allows the creation of more complicated pipes by combining multiple simpler ones, like submodules.

It has one output, which is the result feed of the corresponding pipe.
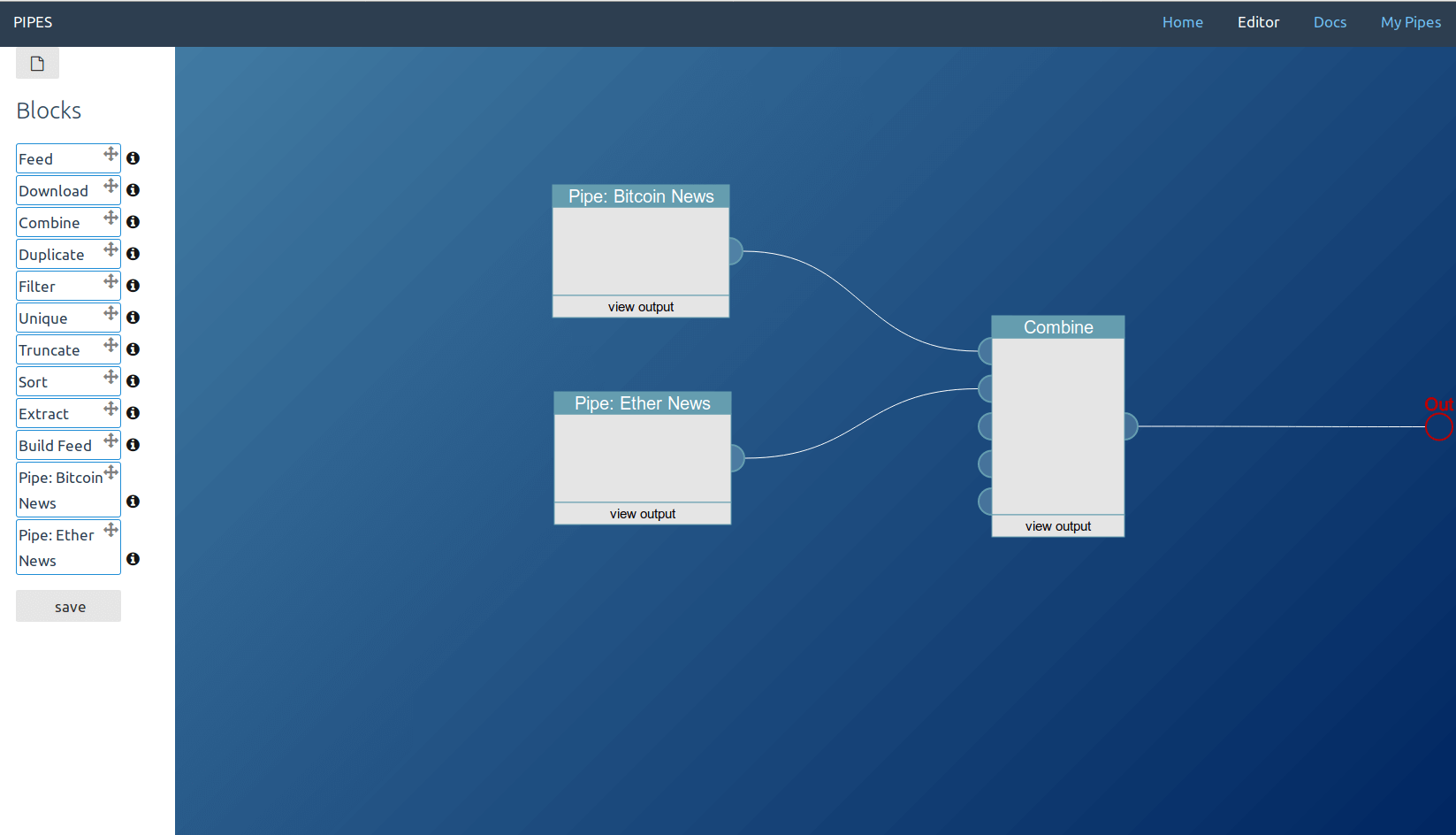
In this example usage, the pipe combines two filtered feeds that are created by other pipes.
Webhook
Use data sent by a webhook as pipe input. When you create this block, it will show a URL, which is your new webhook endpoint. You can instruct other sites - like Github - to POST data to that endpoint. The webhook block will create a feed out of the received data, which can then be manipulated as usual. Note: Stored data is erased after an hour, and the API endpoint is rate limited (currently to 5 requests per minute).
It has one output, which is the data stored under its webhook endpoint.
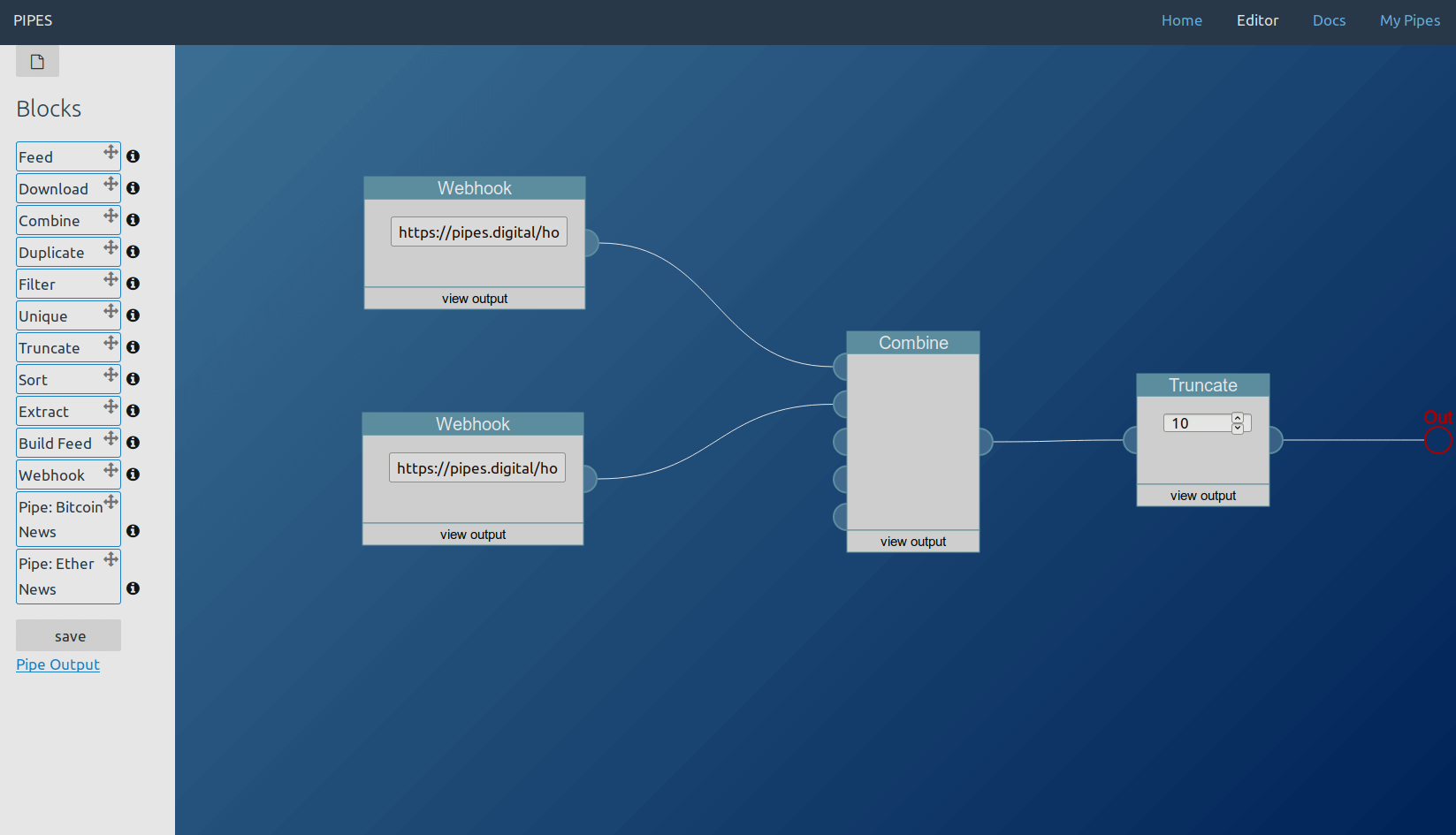
In this example usage, the pipe combines two webhook feeds and limits the length to the last 10 items.
Textinput
Use this block to let other users fill the input of connected blocks. This can make a pipe dynamic. For example, you could have a generic pipe that works with many sites, and this way other users could point the pipe to the site they want to use it on.
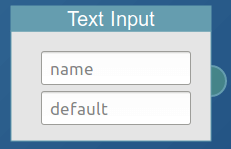
The first user input is the name of the input. It will be shown to the user in the UI and is also the name of the GET parameter that controls this block when calling the pipe feed. The second user input is the default value that will be used when the parameter is not set. It has one output, which is the text that will be used by the connected input.
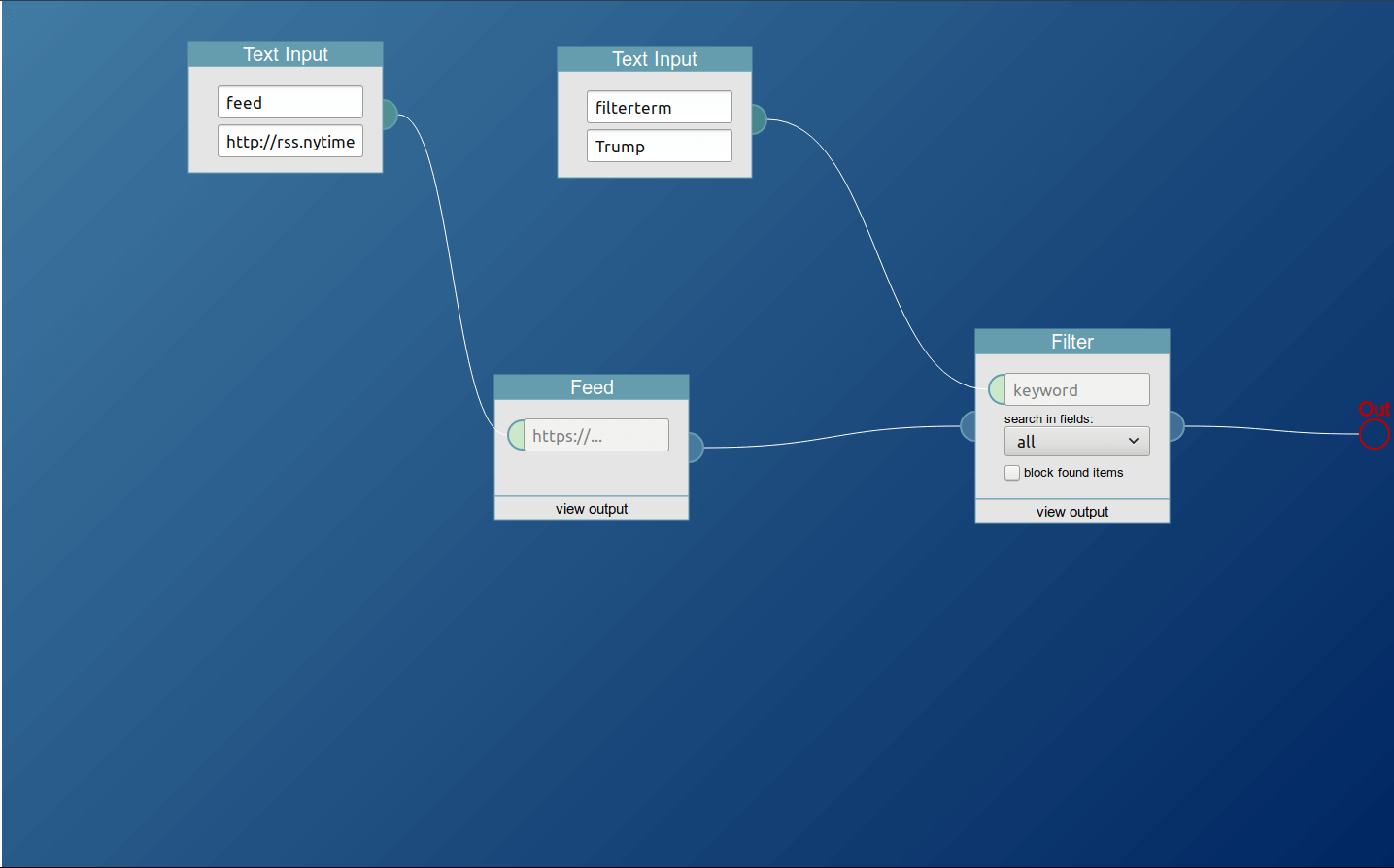
In this example usage, the pipe filters a user-choosable feed for a search term the user selects as well. The default feed is the one from the New York Times, and the default search term is Trump. That pipe can be found here.
ForEach
Use this block to repeat the action of a download or feed block for every item of the input feed. Those blocks normally work with the user provided text input, to download a specific url for example. With the ForEach block, instead of acting on a single manually provided URL you could download all the URLs you extract from somewhere else. This can for example be useful to create full text RSS feeds. To control the action of the block, drop a download or feed block on it.
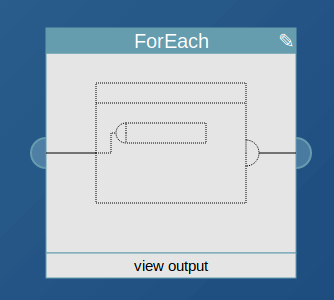
The block takes the items it is supposed to act upon as input, usually provided by an extraxt block. It outputs the downloaded URLs (as items in an RSS feed) or fetched feeds (with all the items appended), depending on its configuration.
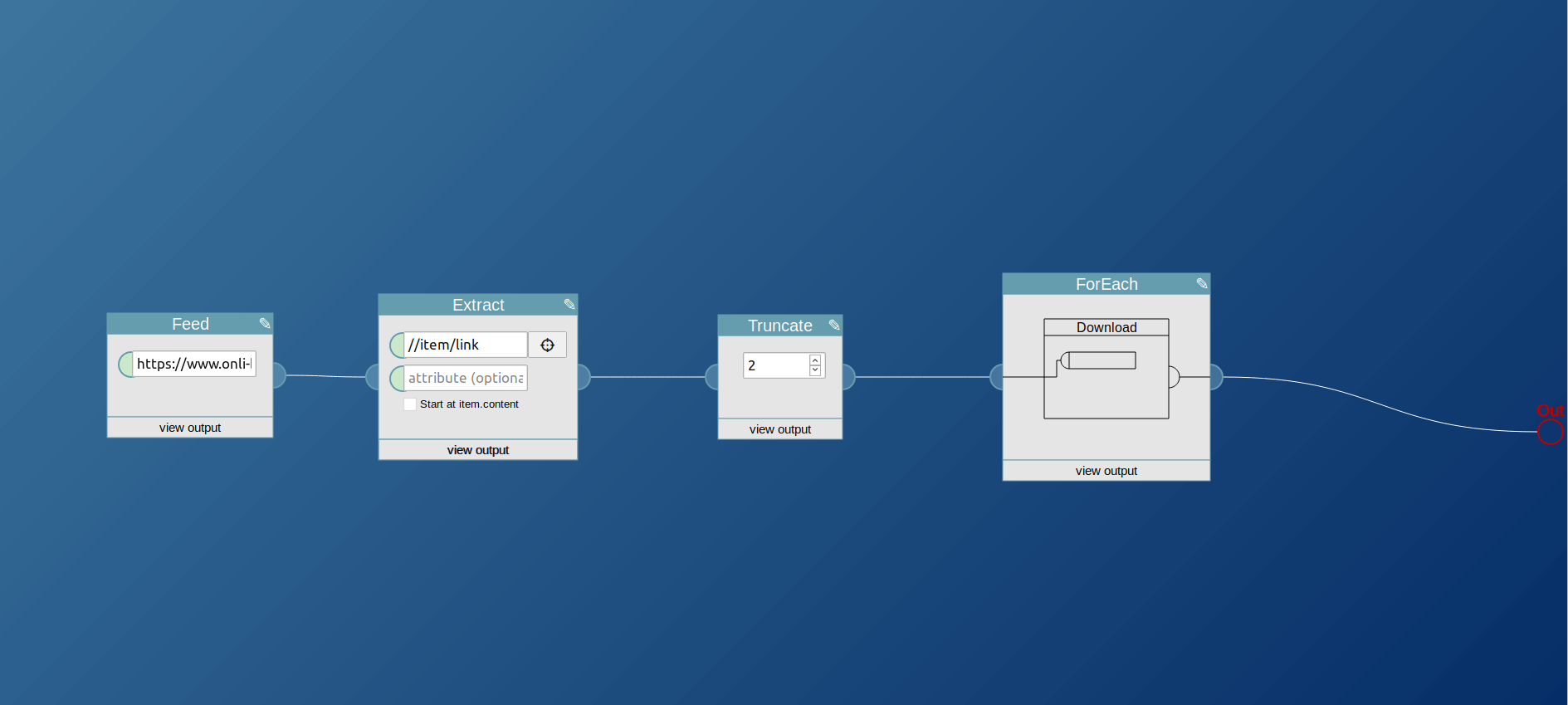
In this example usage the block is configured as download block. The output will be the first two pages linked in the RSS feed of onli-blogging.de.
Tweets (legacy)
As there is no trustworthy model for further access to the twitter API, the twitter block is now defunct.
Integrations
Pipes has blocks to fetch data comfortably from some other sites. Those service specific blocks usually take a user or channel name or an url. They then return a normalized RSS feed with updates specific to the target site. Currently supported sites are:
- Vimeo
- Dailymotion
- Periscope
- Mixcloud
- SVT Play
- Speedrun.com
- Youtube, integrated into the Feed block
Pipes does not have a special agreement with those sites. It just accesses (hidden) existing RSS feeds or uses APIs to create them. For some of those blocks Pipes calls RSS Box to do the feed discovery and creation work.